
What is Data Science and Data Analytics?
Data Science is a field of Information Technology and Computer Science where we analyze data using different programming models and tools. It is a science that is moving around the “data loading” and “data processing” using the latest tools and technologies. Data is raw facts that do not have any meaning but if we analyze data sets then we will produce some meaningful information so professionals are using python and Scala programming language to produce meaningful results in the form of graph and charts like stock market data analysis, real-time fraud detection, spam detection in email, image processing, etc. Let us take a deep dive to understand What is Data Science.
Data Science is not a new field or domain as from past decades we are mining, extracting, and analyzing information using various traditional tools.
Data Science Field has a couple of sub-modules listed below.
1-Big Data Distribution at Cluster.
Nowadays many organizations moving towards big data tools like Hadoop and Apache Spark, these are big data frameworks for a huge amount of data processing, both works in a distributed computing environment where Hadoop keep big data at their cluster having a couple of machines stores data after partitioning and spark read data from Hadoop file system and process it in a distributed manner at distributed RAM.
Hadoop has an architecture of distributed file system where it keeps data on multiple machines, for example, say you want to load 500MB data at Hadoop file system then it will automatically divide your data into 4 parts
(part-1 of 128 MB,part-2 of 128 MB,part3 of 128 MB,part-4 116 MB) as one memory block size in Hadoop is 128 MB.
2-Data Preprocessing & Filteration.
Data Preprocessing and filtration is the first concern in data processing as many machine learning model in data science does not work on textual values so we need to prepare meaningful data sets for machine learning model. Data Scientist divides their data sets into two parts (training and test) so first, they prepare a machine learning model using training data set and then finally pass test data set inside the model to predict and calculate errors in machine learning models.
For text classification you need to filter some words like is, am, was, were, etc so that you can perform an operation on actual worlds that are required to process.
3-Data Loading ( ETL)
We have a lot of ETL tools that load data from various servers where Apache Sqoop is used to load batch data into the Hadoop echo system and Apache Flume or Kafka is used to make a robust data pipeline for real-time
data loading from servers. Sqoop uses the JDBC approach to make connections from various relational database management systems like MySQL, DB2, Oracle, etc.
ETL means extract transform and load so professionals make connections from RDBMS like oracle and load their huge volume of data at the data warehouse. Apache Hadoop provides a data warehouse facility where you can load a huge amount of data and finally they process their data from tools like apache hive and apache spark.
4-Data Visualization.
Report Generation is a major concern after data analysis so professionals use various tools to generate a final report in the form of graphs and charts like python matplot library is used to generate graphs and some of the organizations are using Tableau or apache zeppelin. These chats define relationships and the status of various columns present inside the processed results.
5-Real-Time Data Analysis.
weblogs data analysis is an example of real-time data processing where we are collecting logs data from servers like apache and process these logs in real-time. real-time data analysis is becoming a trending analysis nowadays most of the organization are generating their real-time data pipeline using Apache Kafka and processing data using spark streaming module.
here is a practical example of real-time data analysis using apache spark.
https://www.techbook.in/real-time-processing-in-spark/
6-Batch Data Analysis.
In Batch Data loading and processing we collect data from various sources like RDBMS and load it in a timely manner like weekly data loading at the data warehouse, Apache hive provides a data warehouse facility where hive keep data at the distributed file system.
Professionals use various batch data processing techniques like partitioned and buckets where we divide data according to some conditions that make SQL queries faster on partitions and buckets.
7-Machine Learning.
Machine Learning is a field of statistics and data analysis where professionals train ML models from data sets and then test their different models using fresh data sets. regression, classification, and clustering models are used to analyze different datasets.
Machine Learning is a part of data science where we develop a model for data analysis that is based on the training data sets so we need to train our ML model using Training data sets (part of actual data sets) and finally we test the accuracy of our model using Test data sets (might be a part of actual data sets) then we try to reduce our model errors using gradient descent and other models.
Example:
1-Regression Analysis (Linear Regression )
2-Classification Techniques ( Logistic Regression)
3-Clustering ( K mean Clustering)
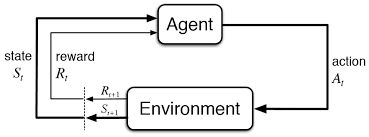
8-Reinforcement Learning & Artificial Intelligence.
Reinforce Learning is a method of Artificial Intelligence where the system tries to learn from its own mistakes and produces a better result after every mistake.
Example: The computer is playing a chess game by itself.
List of tools and technology that are used to process data.
Programming languages.
1- python Programming
2-Java Programming.
3- Scala Programming.
we can use various programming languages to analyze data but python is tremendously growing and many professionals and IT Organizations opting for python programming as a base language for data analysis.
Frameworks for Big Data Processing.
1- Apache Hadoop Echo System. (Cloudera, IBM)
2- Apache Spark Echo System.
Hadoop and Spark Both are Data processing Frameworks having a couple of tools that are used to process different varieties of data sets. Hadoop processes data into a disk while the spark might process data into RAM and Disk Both.
Apache Hadoop is not meant for Small data Processing it is a framework that is meant for Big Data (A huge amount of data that can not be processed using traditional tools.)
Data Loading Tools.
1- Apache Sqoop
2- Apache Flume
3-Apache Kafka
Visualization Tools.
1- Matplotlib ( A python library)
2-Apache Zepplin Server.
3-tableau
Tools for Data Processing and Analysis.
1-Apache Hive
2-Apache Pig
3- Spark SQL.
4-Spark Streaming.
Thank You.