
real-time data processing using spark
Apache Spark is a framework for big data processing that works in a
distributed computing environment and process data on distributed RAM. spark has a very popular module Spark Streaming.in this blog, we are going to discuss how we can do real-time data processing using spark streaming module.
I am assuming that you have a Cloudera Hadoop distribution environment so as a beginner you can start learning on the terminal but you need to understand the module functionality.
Let us understand what is real-time data processing.
many organizations are working on real-time data processing using spark and they are getting this real-time data from various servers like real-time log processing of web servers, real-time transactions processing, real-time fraud detection analysis, etc so real-time the data processing means to analyze and process data at the same time while you are getting it on the server.
Now the question is how we can collect real-time data from servers.
we can collect it from network sockets so spark streaming module gives us features to access data from sockets.
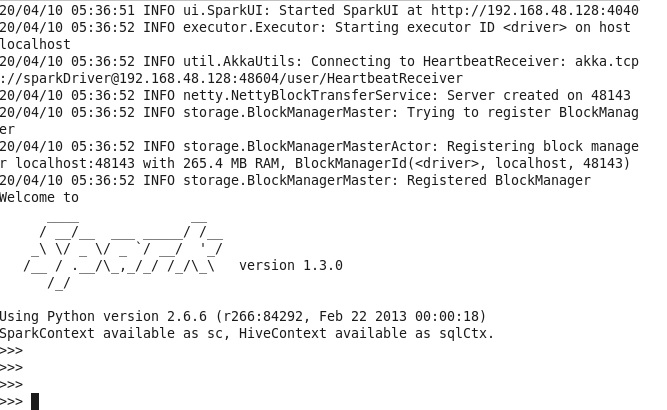
run pyspark command to launch pyspark in Cloudera
pyspark <hit enter>
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc,10)
lines = ssc.socketTextStream(“localhost”, 9999)
words = lines.flatMap(lambda line: line.split(” “))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.saveAsTextFiles(“file:///home/cloudera/Desktop/myoutput”);
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
then copy and paste this code in python shell so in this code we are creating an object of StreamingContext class and defining host and port number of the server. you can change the localhost to the IP address of your server machine so this code will get data from 9999 socket of the local server.
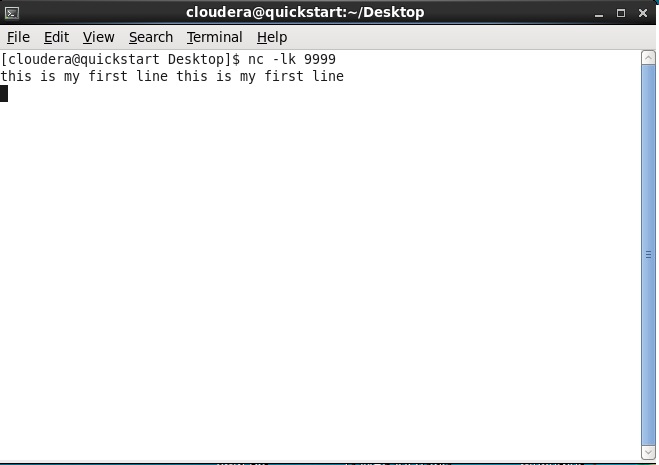
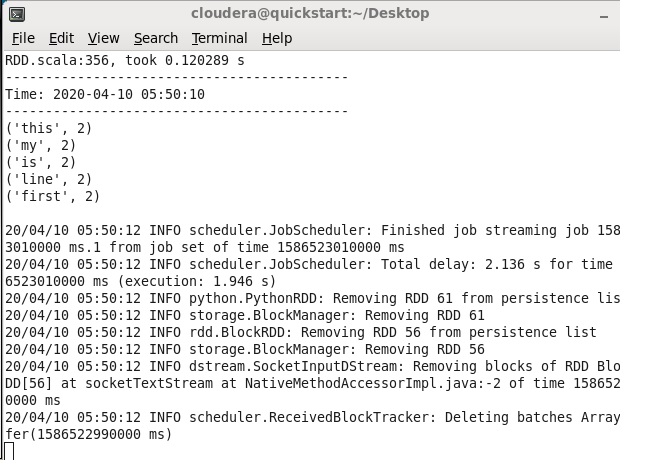
so inside lines variable, we will get a dstream ( sequence of RDD’s) sequence of lines that is real-time data let us assume file size is 1GB so in every 10 seconds, this code will hit the socket and will collect the data from the socket.
finally, this code will perform wordcount operation on every line.
then launch a new terminal and load data on 9999 socket using the below command.
tail -f inputdata.txt | nc -lk 9999
where inputdata.txt is a file having a couple of lines that you want to process.
THANK YOU.