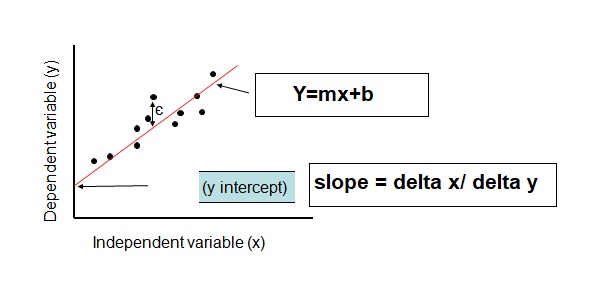
The goal of Linear Regression is the find the best fit line in the given datasets and using this line be can predict future value so you need to calculate slope of this line and intercept of the line.now the question is how you can say that your line fits best in the the given datasets so we calculate SSE that is sum of square error and this SSE should be minimum then you can say your line fits best for a given data set.
Let us say we have two variable x (area in sq ft) and y (price of a flat)
x= { 1,2,3}
y= {3,2,4}
SSE = (( mx+b) – y’) power 2
where mx+b is predicted value and y’ is actual value
SSE = ( m*1+b-3) power 2+(m*2+b-2) power 2+ (m*3+b-4) power 2
After taking derivative now.
de/dm= 2* ( m*1+b-3) +2* (m*2+b-2)* 2+ 2* (m*3+b-4) *3
=28m+12b-38=0
de/db= 2* ( m*1+b-3) +2* (m*2+b-2)+ 2* (m*3+b-4)
=12m+6b-18=0
m=1/2 and b=2
Example:
Linear Line Eq: y=mx+b
so now our equation is y=x/2+2 that will predict y values.